Cours Architecture des ordinateurs en PDF (Avancé)
Vous souhaitez télécharger le cours PDF Architecture des ordinateurs (127 pages) pour approfondir la microarchitecture ? Télécharger le PDF (127 pages)
Introduction à l'architecture des systèmes numériques. Le document décrit l'organisation et l'interaction des composants matériels et des interfaces logicielles : portes logiques CMOS, chemin de données, ISA, hiérarchie mémoire et gestion des interruptions. Le PDF inclut des exercices corrigés et des sujets de travaux pratiques sous Logisim pour vérifier les acquis par simulation et debugging de circuits numériques. Une section introductive met l'accent sur les additionneurs en tant qu'exemple clé de circuits combinatoires utilisés dans l'unité centrale d'un microprocesseur et leur impact sur la conception d'une ALU.
🎯 Ce que vous allez apprendre
- Codages et arithmétique binaire — représentations positionnelles (base 2, base 16), codage des entiers signés (two's complement et variantes), formats fixed-point et floating-point (ex. binary‑16). Ces notions facilitent la conception d'ALU et la détection d'overflow au niveau matériel.
- Électronique numérique et portes logiques CMOS — transistors CMOS, inverseur, portes NAND/NOR, niveaux logiques, temps de propagation et chemin critique. Approche pratique pour estimer la latence d'un bloc logique.
- Circuits combinatoires et unités arithmétiques — décodeurs, multiplexeurs/démultiplexeurs, ROM, additionneurs (ripple, carry‑lookahead) et conception d'une ALU pour entiers et virgule flottante. Le PDF propose des exercices et TP Logisim ciblés sur la mise en œuvre et le test d'additionneurs en architecture.
- Logique séquentielle et organisation du chemin de données — bascules RS/D, registres, mémoire RAM, contraintes d'horloge et synchronisation ; principes de séquencement et stabilité des fronts d'horloge.
- Couche ISA et microprogramming — codage des instructions, fetch, machines à états finis pour le séquencement, et micro‑instructions ; utilisation pour traduire un jeu d'instructions en micro‑séquences.
- Hiérarchie mémoire et cohérence de cache — types de mémoire, principe de localité, caches (direct mapping, fully/associative, n‑ways), étiquettes/ensembles/lignes et politiques de remplacement ; évaluation des compromis capacité/latence.
- Pile, procédures et gestion des interruptions — convention d'appel, passage d'arguments, pointeur de pile et gestion des interruptions ; analyse du flux d'exécution en présence d'interruptions.
- Pratique et TP sous Logisim — sujets de travaux pratiques pour simuler portes, registres, ALU, additionneurs et machines à états finis, favorisant la synthèse et le debugging de circuits numériques.
📑 Sommaire du document
Composants fondamentaux
- Processeur (CPU) — exécute les instructions et orchestre les échanges entre unités fonctionnelles.
- Unité Arithmétique et Logique (ALU) — réalise opérations arithmétiques et logiques ; inclut additionneurs et circuits combinatoires critiques pour la latence.
- Registres — stockage rapide interne au processeur pour opérandes et états intermédiaires, utilisés par l'ALU et le séquenceur.
- Mémoire vive (RAM) — stockage volatile accessible par la hiérarchie mémoire ; interactions avec caches et contrôleurs mémoire.
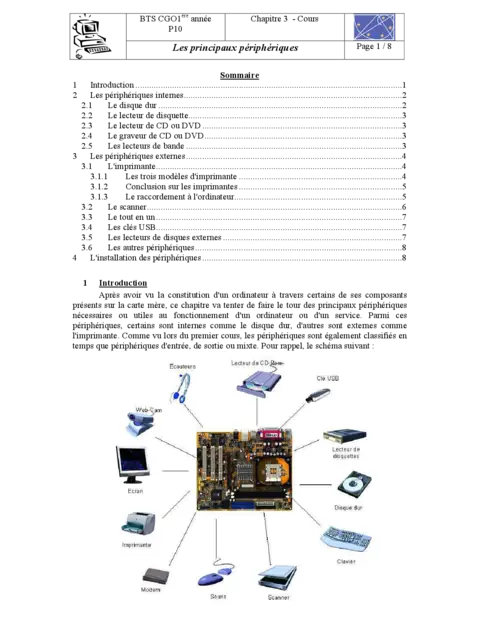
Les composants internes de l'ordinateur
Les composants internes décrivent l'ensemble des éléments constitutifs d'une unité centrale : unité de contrôle, ALU, registres et chemins de données. Les additionneurs, exemples typiques de circuits combinatoires, illustrent le compromis performance/complexité au cœur du microprocesseur. L'analyse porte sur la mise en œuvre (ripple vs carry‑lookahead), l'impact sur le chemin critique et les choix d'optimisation pour réduire la latence sans compromettre la stabilité de la fréquence d'horloge.
Composants matériels et périphériques
La liaison entre le microprocesseur et les périphériques repose sur des interfaces matérielles et logicielles : ports I/O, bus et mécanismes d'interruption. Le texte détaille comment le CPU orchestre les échanges via accès mémoire ou entrées/sorties mappées, ainsi que la gestion des interruptions matérielles et leurs implications sur la latence et la cohérence des données lors d'écritures multiples.
Les périphériques d'entrée/sortie—souris, clavier et écran—jouent un rôle essentiel dans le flux d'information : ils génèrent événements (interrupts), nécessitent mécanismes de bufferisation et contrôleurs DMA pour minimiser l'occupation CPU, et influent sur les stratégies de gestion des files d'attente et des priorités d'interruption. Le document présente des schémas de buffering et des recommandations pour réduire la latence et éviter la perte de données lors d'accès concurrents.
Exercices et TP Logisim inclus
Le support propose des sujets de TP exploitables sous Logisim et des exercices corrigés permettant de mettre en pratique la théorie : conception d'additionneurs et d'ALU, simulation de machines à états finis, implémentation d'un séquenceur microprogrammé et tests de stratégies de cache. Ces ressources facilitent la transition entre spécification formelle et simulation fonctionnelle et sont accompagnées d'indications pour exécuter les TP avec la ligne de commande et Logisim.
💡 Pourquoi choisir ce cours ?
Rédigé par Jeremy Fix, le support présente une progression pédagogique du niveau des bits jusqu'à l'ISA, illustrée par schémas (TikZ) et travaux pratiques reproduisibles sous Logisim. La méthodologie privilégie exercices corrigés et séances de simulation pour valider les acquis progressivement et faciliter l'application dans des projets embarqués.
👤 À qui s'adresse ce cours ?
- Public cible : étudiants en informatique et électronique, ingénieurs systèmes embarqués et développeurs bas niveau souhaitant approfondir la microarchitecture et la conception de circuits numériques.
- Prérequis : notions de logique combinatoire et algèbre booléenne, connaissances élémentaires en programmation impérative (assembleur/compilé) et familiarité avec la ligne de commande pour exécuter les TP.
❓ Foire Aux Questions (FAQ)
Quelle différence entre complément vrai et complément réduit ? Le two's complement (complément vrai) permet d'effectuer additions et soustractions sans logique spéciale de signe, simplifiant la détection d'overflow via les bits de retenue et les drapeaux. Le document illustre l'impact de ces codages sur l'ALU et le traitement des dépassements arithmétiques.
Comment la cohérence du cache est-elle traitée ? La cohérence est présentée en relation avec les stratégies d'accès mémoire et le mapping (direct, associatif, n‑voies) : notions d'étiquette, d'ensemble et de ligne, et conséquences des écritures multiples. Les chapitres aident à choisir une politique de remplacement adaptée selon contraintes de latence et de capacité. Pour aller plus loin, vous pouvez consulter notre Cours Circuits et architecture des ordinateurs ou découvrir les supports de stockage utilisés dans les systèmes informatiques.