Cours de Le modèle client-serveur en PDF (Intermédiaire)
Le modèle client-serveur : Architecture réseau répartissant les tâches entre fournisseurs de ressources (serveurs) et demandeurs (clients), applicable à l'architecture distribuée. Ce document PDF de 60 pages, rédigé par Christian Bulfone, présente les concepts indispensables pour une utilisation et une mise en œuvre efficaces en contexte professionnel et académique.
🎯 Ce que vous allez apprendre
- Principes du modèle client-serveur : Compréhension du cycle requête / réponse et des échanges entre composants.
- Fonctionnement des serveurs : Rôle, exigences et interactions avec les ressources (ex. serveur de base de données).
- Avantages de l'architecture : Sécurité, évolutivité et maintenance centralisée.
- Exemples d'applications : Types de serveurs et cas d'usage.
- Gestion des processus : Interaction entre processus clients et serveurs dans des systèmes distribués.
- Administration et centralisation : Aspects opérationnels et de supervision des infrastructures réseau.
Principes du modèle client-serveur
Le fonctionnement repose sur un cycle simple : le client envoie une requête vers un point d'accès (par exemple une requête HTTP), le serveur traite la demande — éventuellement en interrogeant un serveur de base de données — puis renvoie une réponse. Cette séquence permet l'interopérabilité entre composants hétérogènes et facilite la distribution des tâches au sein de systèmes distribués, tout en permettant une gestion centralisée des services et des données.
Protocoles et communication réseau
- TCP/IP
- HTTP
- FTP
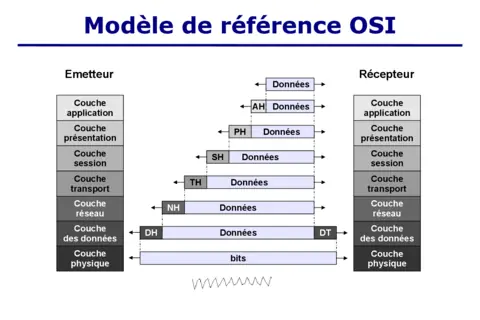
Le modèle client-serveur s'appuie sur des protocoles qui opèrent à différents niveaux de la pile réseau. Sur le plan conceptuel, les échanges applicatifs (messages structurés, API, pages web) se situent au niveau de la couche Application ; le transport des octets est assuré par TCP/UDP en dessous. Dans l'architecture TCP/IP, les services sont identifiés par une adresse IP et un numéro de port : le couple adresse:port permet d'atteindre un service précis sur un hôte (ex. port 80 pour HTTP, 443 pour HTTPS, 22 pour SSH). Les numéros de ports distinguent les services réseau sur un même serveur et constituent un élément clé pour la configuration des pare-feux, des proxys et des règles de redirection. Comprendre le rôle de chaque protocole facilite l'analyse des logs, le diagnostic des performances et la mise en œuvre de mécanismes de sécurité (chiffrement, authentification, contrôle d'accès) et de scalabilité tels que le load balancing.
Architecture Multi-tiers
L'évolution vers une architecture multi-tiers dissocie la présentation, la logique applicative et la gestion des données (3-tier). Cette séparation améliore la scalabilité, la maintenance et la sécurité : la couche présentation s'adresse aux clients, la couche applicative centralise la logique métier, et la couche données centralise le stockage (serveur de base de données).
👤 À qui s'adresse ce cours ?
- Public cible : Étudiants et professionnels souhaitant approfondir l'architecture réseau et les pratiques de conception applicative (niveau Intermédiaire).
- Prérequis : Connaissance des bases de l'informatique (systèmes d'exploitation, notions de réseaux) recommandée.
La gestion de la concurrence et des accès simultanés
Un serveur doit gérer des requêtes concurrentes provenant de multiples clients sans compromettre l'intégrité des données ni la disponibilité du service. Les stratégies courantes incluent le traitement synchrone par file d'attente, le traitement asynchrone avec workers, et l'utilisation de mécanismes de verrouillage (locks) ou de transactions pour assurer la cohérence. La conception doit prendre en compte la latence, la tolérance aux pannes et la scalabilité horizontale pour monter en charge. Le choix entre requête synchrone et modèles non bloquants dépend des contraintes de latence et des ressources disponibles.
Gestion de la concurrence
La gestion de la concurrence se matérialise par deux approches principales : multi-threading et multi-processus (fork). Le multi-threading permet à plusieurs threads d'un même processus de partager la mémoire pour des échanges rapides, tandis que le multi-processus isole davantage les exécutions, réduisant l'impact d'une défaillance. En pratique, on combine souvent un front-end asynchrone, une couche de workers et un ordonnanceur de tâches pour équilibrer la charge et limiter les verrous. Les architectures distribuées utilisent des files de messages et des pools de connexions pour coordonner l'exécution et garantir la résilience.
Exemples de serveurs courants
- Serveur de fichiers (FTP/SMB)
- Serveur Web (HTTP)
- Serveur de base de données (SQL)
- Serveur de messagerie (SMTP)
Implémentation technique : Sockets et Ports
La communication client-serveur au niveau programmation s'appuie sur des sockets : points d'entrée réseau qui lient une adresse IP à un numéro de port. Un socket serveur écoute un port particulier et accepte des connexions entrantes ; un client ouvre un socket vers cet hôte:port. Les environnements UNIX/Linux sont historiquement liés à la programmation des sockets et illustrent la gestion des processus (démon, descripteurs de fichiers, fork/exec). La plupart des exemples pratiques du cours s'appuient sur ces systèmes et montrent comment ajouter la gestion des erreurs, le multi-threading ou l'utilisation d'un serveur asynchrone pour la montée en charge.
Exemple minimal en Python d'un serveur TCP acceptant une connexion :
import socket
srv = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
srv.bind(('0.0.0.0', 8000))
srv.listen(1)
conn, addr = srv.accept()
data = conn.recv(1024)
conn.sendall(b'HTTP/1.1 200 OK\r\nContent-Length: 2\r\n\r\nOK')
conn.close()
srv.close()Ce fragment illustre l'adressage par numéros de ports et la logique d'acceptation des connexions. En production, on ajoute la gestion des erreurs, le multi-threading ou l'utilisation d'un serveur asynchrone pour la montée en charge.
Comparaison : Client-Serveur vs Peer-to-Peer
Dans une architecture centralisée, les services sont fournis par des nœuds dédiés (serveurs) et l'administration se fait de manière centralisée. En P2P, chaque nœud peut être à la fois client et fournisseur, ce qui favorise la résilience mais complique la gestion, la sécurité et la cohérence des données. Le choix dépend des besoins en contrôle, montée en charge et tolérance aux pannes.
❓ Foire Aux Questions (FAQ)
- Qu'est-ce qu'un modèle client-serveur ?
- Architecture où des clients envoient des requêtes à des serveurs qui fournissent des services ou des ressources, permettant une gestion centralisée des fonctions et des données.
- Quels sont les avantages de ce modèle ?
- Meilleure sécurité et contrôle, unicité de l'information, évolutivité et facilité de maintenance grâce à la centralisation des services.
- Quelle est la différence entre le modèle client-serveur et le Peer-to-Peer (P2P) ?
- Le modèle centralisé s'appuie sur des serveurs dédiés et une administration unifiée ; P2P distribue les rôles entre pairs, améliorant la résilience mais réduisant le contrôle centralisé et la simplicité d'administration.