Cours Bases de données en PDF (Avancé)
Bases de données - Modèles et langages : Discipline informatique qui formalise la représentation, le stockage, la manipulation et la protection des données à l'aide de modèles abstraits (relationnel, entité-association) et langages (SQL, PL/SQL) pilotant un SGBDR (Système de Gestion de Bases de Données Relationnelles). Maîtriser ces notions permet de concevoir des schémas fiables, d'écrire des requêtes correctes et performantes, et d'assurer l'intégrité et la concurrence des accès en production. Ce document au format PDF est proposé gratuitement et contient des exemples, ateliers et exercices exploitables pour un apprentissage pratique.
🎯 Ce que vous allez apprendre
- Modèle relationnel et notions fondamentales — définition précise d'une relation, du nuplet et du schéma relationnel, accompagnée de la notion de clé et de clé étrangère; ces concepts sont essentiels pour garantir l'unicité et l'intégrité référentielle, et vous saurez formaliser un schéma répondant aux contraintes métier.
- Dépendances fonctionnelles et normalisation — identification des dépendances fonctionnelles et application pratique des formes normales avec un algorithme de normalisation; comprendre pourquoi un schéma est décomposé améliore la qualité des données et réduit les anomalies d'insertion, mise à jour et suppression.
- SQL déclaratif et logique — passage du calcul propositionnel et des prédicats vers des requêtes SQL conjonctives et quantifiées; vous apprendrez à traduire des contraintes logiques en clauses
SELECT ... FROM ... WHEREet à raisonner sur l'équivalence des requêtes. Le cours aborde également les composants du langage SQL : DDL (Data Definition Language) pour la structure, DML (Data Manipulation Language) pour les opérations sur les données et DCL (Data Control Language) pour les permissions et le contrôle d'accès. - Algèbre relationnelle et optimisation — opérateurs algébriques (
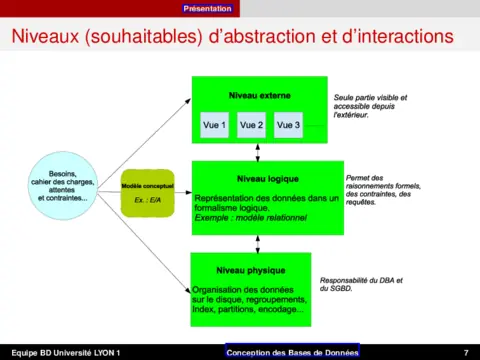
π,σ,×,∪,−) et jointures (opérateur⋊⋉), résolution des ambiguïtés et réécritures d'expression; ces outils vous permettront d'analyser les plans de requête et d'appliquer des transformations en vue d'optimisation, indispensables pour l'optimisation des plans d'exécution. - Conception avec le modèle Entité-Association — modélisation E/A (entités, attributs, identifiants, associations binaires, entités faibles, spécialisation) et traduction vers un schéma relationnel; vous saurez produire un MCD cohérent et appliquer la normalisation lors de la transformation en tables relationnelles.
- Transactions, ACID et niveaux d'isolation — propriétés ACID, effets indésirables des exécutions concurrentes, recouvrabilité et choix des modes d'isolation SQL (read committed, repeatable read, serializable); vous pratiquerez ces concepts via expériences avec un SGBD et un atelier en ligne dédié aux transactions pour évaluer l'impact sur la sérialisabilité et les verrous.
Maîtrise du SQL : DDL, DML et contrôle de données
Le cours détaille le langage de définition (DDL) pour la création et la modification de schémas (tables, index, contraintes), le langage de manipulation (DML) pour les opérations INSERT, UPDATE, DELETE et les requêtes SELECT, ainsi que le contrôle des accès via DCL (GRANT, REVOKE). Des exercices pratiques montrent comment concevoir les contraintes d'intégrité et gérer les transactions en conjonction avec les commandes DDL/DML pour préserver l'intégrité des données lors des opérations de maintenance et des migrations.
Architecture et optimisation des SGBDR
Présentation des composants classiques d'un SGBDR : moteur de stockage, gestionnaire de transactions, optimiseur de requêtes et gestion des verrous. La section explique comment l'optimiseur transforme une requête SQL en plan d'exécution, comment mesurer le coût des opérateurs et quelles transformations d'algèbre relationnelle favorisent des plans plus efficaces. Des cas concrets illustrent l'impact des index, des statistiques et des heuristiques d'optimisation sur le débit et la latence des requêtes.
📑 Sommaire du document
- Introduction
- Le modèle relationnel
- SQL, langage déclaratif
- SQL, langage algébrique
- Conception d’une base de données
- Schémas relationnel
- Procédures et déclencheurs
- Transactions
💡 Pourquoi choisir ce cours ?
Avantage clé : l'approche combine rigueur théorique et ateliers pratiques : quiz, exercices guidés, un atelier d'installation SGBD (MySQL) et une interface en ligne pour expérimenter les transactions sont intégrés. L'auteur, Philippe Rigaux, structure le contenu en modules progressifs couvrant le modèle relationnel, l'algèbre relationnelle, SQL (déclaratif et algébrique) et PL/SQL, avec des exemples de syntaxe et des cas d'utilisation. Le document met l'accent sur la qualité du schéma (dépendances, normalisation) et sur la compréhension des mécanismes de concurrence et d'isolation, ce qui distingue ce support des simples mémos syntaxiques. Le cours est compatible avec les principaux SGBD du marché : PostgreSQL, Oracle, MySQL et SQL Server.
👤 À qui s'adresse ce cours ?
- Public cible : étudiants en informatique et professionnels (développeurs back-end, ingénieurs données, administrateurs de bases) qui conçoivent ou optimisent des bases de données relationnelles en contexte d'application réelle.
- Prérequis : notions de programmation et d'algèbre des ensembles, connaissance de base de SQL, compréhension élémentaire de la logique (prédicats et quantificateurs) et capacité à utiliser un SGBD en ligne de commande pour les ateliers.
Questions fréquentes sur les bases de données
Comment les dépendances fonctionnelles sont-elles exploitées pour la normalisation ?
Le texte formalise les dépendances fonctionnelles et propose un algorithme de décomposition qui garantit la suppression des redondances tout en préservant la perte minimale d'information; l'étudiant apprendra à détecter les FDs, à produire des schémas en 2NF/3NF et à raisonner sur la préservation des dépendances.
Quels critères pour choisir un niveau d'isolation SQL dans une application ?
Le cours compare read committed, repeatable read et serializable en termes d'anomalies (lectures non répétables, phantom reads) et de coût de synchronisation; la decision repose sur l'exigence de sérialisabilité, la tolérance aux anomalies et l'impact sur le débit lié aux verrous et à la recouvrabilité.